BEIJING, Dec. 21, 2019 /PRNewswire/ -- Magic Data Technology Chinese Mandarin Conversational Speech was selected into LDC Catalog. The catalog ID of this dataset is LDC2019S23 (browse at https://catalog.ldc.upenn.edu/LDC2019S23 for details). At the beginning of this month, LDC published this news to its subscribers through December newsletter.
New trends for conversational datasets
As the leading companies such as Google, Amazon pay more attention to continuous conversation, the importance of conversational datasets increases. Besides, the accuracy of read speech data recognition is up to 97-98%, but in conversational speech recognition, the accuracy is nearly 50% (referred to results of the CHiME-5 Challenge). This large gap indicates the challenge in automatic speech recognition (ASR) extend to new phase.
This is an excellent testing dataset for conversational speech recognition models.
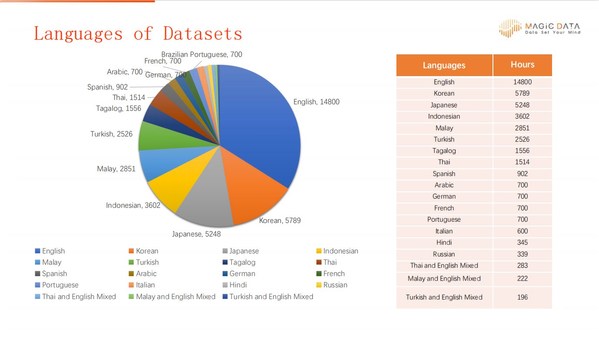
There are three key words for this corpus, diversity, accuracy and variety. Diversity is for data collection, which means these data are collected to cover conversations recorded in different accents and transmission channels, with speakers of different ages and genders and with a background noise corresponding to the scenario. Below are some details:
The second key word accuracy is for data annotation. Magic Data Technology has formulated a series of tagging rules to meet actual needs. What does it mean? Spontaneous conversation produces overlapping, pause, cough, and clapping. These sounds are meaningful in some conditions as they may indicate the speaker's state, mood, and even hint at the speaker's mental activities. According to the company's advanced annotation specifications, these sounds could be recognizable by AI systems.
The last key word variety is for data application. This corpus is valuable for at least 3 applications: conversational speech recognition, speaker separation, speaker verification and robustness testing.
The accuracy of AI algorithms depends on a large amount of relevant data. Data quality undoubtedly has a decisive influence on its accuracy and practicability. Among them, the variety of data and its relevance to the real business are the two most important factors. The corresponding data collection, integration and application capabilities are the focus of the industry.
Magic Data Tech owns the largest conversational databases in mandarin Chinese. With the human-in-the-loop data processing platform and 300,000+ flexible annotation resources, the company is able to provide high-quality data with accuracy up to 99%. Through its professionality of data processing, the company has been serving top AI companies and Fortune 500 companies and received good reputations.
Click http://www.magicdatatech.com/ to learn more about Magic Data Tech.
Tel: +86-10-82527250
Email: business@magicdatatech.com
![]() View original content:http://www.prnewswire.com/news-releases/magic-data-chinese-mandarin-conversational-speech-was-selected-into-ldc-catalog-300978676.html
View original content:http://www.prnewswire.com/news-releases/magic-data-chinese-mandarin-conversational-speech-was-selected-into-ldc-catalog-300978676.html